How to Play Software as a Team Sport
Make it easy to get your pull requests accepted to OSS or company software projects.
- “Keep it Small” with Task Decomposition
- Work on Multiple Issues in Parallel
- Review Your Own Work
- Get in Regular Communication
- Use the Resources You Already Have
I’ve written before about how to start contributing to OSS and I wrote for the Petabridge blog about “How to Use Github Professionally” - both of those posts were aimed at helping developers who had experience working in private software organizations bring their experience and passion into open source software and more specifically, how to use Github as a platform to do that effectively.
This post is aimed at a different audience: developers who want to play the team sport of software. Regardless of your experience level you can always benefit from improving your ability to work with the other developers.
There are entire volumes of books written on this subject, so I’m not going to broach everything - but I hope you find this approachable, helpful, and useful.
“Keep it Small” with Task Decomposition
One of the most important items from “What Do You Need to Become an Elite Developer?” (2013) is:
Able to break down large projects into small tasks – people don’t launch rockets or build massive systems by setting out to do everything all at once; they break down massive projects into smaller milestones and small, fine-grained tasks. Really strong developers have the ability to visualize the end in mind and the steps for getting there. It’s an essential skill for an architect of any sort.
Why is this important? Building a complete picture of how a software system works in your head - or building a picture of how to create a new software system - is very difficult for most people to do well. Harder still is successfully communicating your vision of how everything works to another developer and having them walk away hearing exactly what you intended. Communication doesn’t scale well with technical complexity.
The solution is simple - we need to break apart large, complex problems or ideas into a sequence of smaller, interrelated ones. In the project management world we call this a “task decomposition.”
A simple example from this Akka.NET issue I just finished working on: “High Idle CPU in DotNetty”
On the surface this seems like a complicated issue - when Akka.Remote (our networking system) isn’t performing much active work it’s using a significantly higher amount of CPU resources than expected. In fact, if you roll back to a previous version of Akka.NET from 1 year earlier we don’t have this issue at all. So what’s the right way to attack this problem?
Start by writing down what we know and breaking down the problem:
- This wasn’t a problem with Akka.NET v1.3.[0,18], therefore it was introduced in Akka.NET v1.4;
- Therefore, we can take a look at some of the changes introduced between 1.3.18 and 1.4 and find the culprit there;
- We should profile an Akka.NET program that uses Akka.Remote and based on what we found in step 2, we know where to look for high CPU utilization when the system isn’t doing much work;
- Based on what we find in the profiler we should try modifying the expensive “hot path” on the CPU;
- We should communicate this entire plan to the other software developers on our team because they might know something we don’t.
Each step is discrete, small, and understandable. This helps make a complex, mysterious problem much more approachable. More importantly - it helps everyone else understand how you are reasoning about the problem!
Task decomposition also scales to much larger development problems, such as a “greenfield project.” In these larger contexts I often use a mind map to recursively decompose a big project into smaller and smaller tasks until I reach something that consists of many small, discrete parts that can be easily consumed and understood.
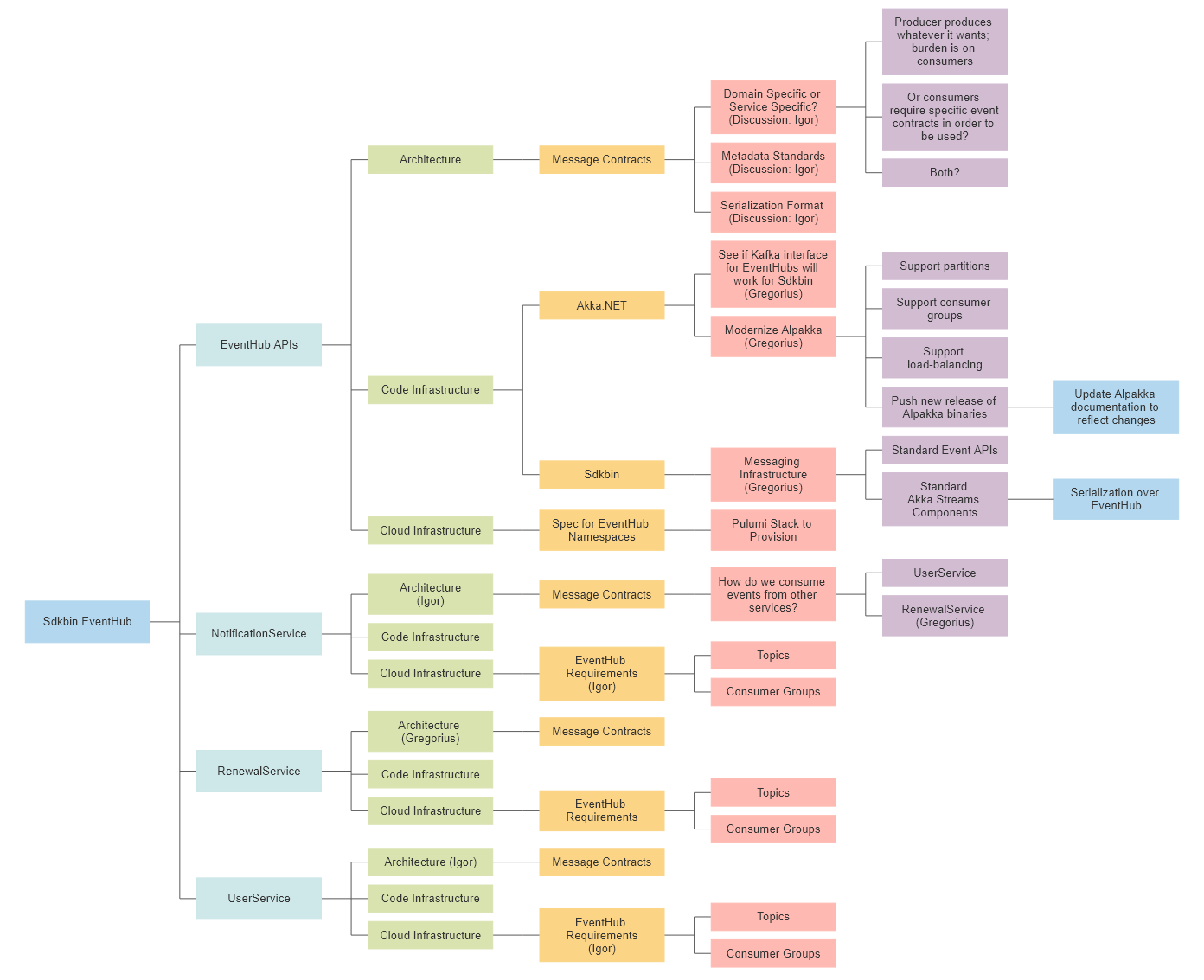
In the above diagram, I needed to help get myself and two other full-time developers on our team organized to work on the development of several new features for Sdkbin - lo and behold, we did this via an initial task decomposition via a mind map. And this isn’t the final state of this work either - each of the individual work items on this diagram will eventually need to be decomposed too once we discover the requirements and agree on some standards for how to approach this project.
Which brings us to our next point.
Work on Multiple Issues in Parallel
One of the biggest inefficiencies in software development is when:
- Developer A is working on item Y;
- Developer B is working on item X;
- Y depends on X; and therefore
- Developer A is currently stuck waiting on Developer B;
The problem here has nothing to do with Developer B - it has to do with either:
- How work is assigned to the individual team members or
- Developer A isn’t doing much to keep themselves busy.
The way to mitigate this issue is to ensure that all developers have multiple issues they can work on in parallel at all times. When work stalls on one issue, for whatever reason, you always have other issues you can work on in parallel.
I personally need to do this with my own work often - I don’t want to get stuck banging my head against the wall on a single issue at any given time, so I work on multiple issues and switch from one to the next. This helps me stay productive but also stops my time from being completely wasted when I’m waiting on someone else to finish an upstream task.
Review Your Own Work
As I mentioned in “How to Use Github Professionally”:
Review Your Own Pull Requests
One of the most difficult skills in programming is reading and understanding other people’s code - this is often because the developer who wrote it knows things the reader does not.
For instance, the developer might have written the code in what at first appears to be a Byzantine way, but it turns out this was necessary in order to avoid a runtime JIT bug the developer ran into during the development process. In an ideal world, developers would use code comments for this exact type of knowledge sharing.
But since you’re reading this and are thus interested in being an more effective programmer, here’s a great thing you can do to help both yourself and your team: review your own pull request first.
One of the easiest ways to ensure that your work gets reviewed quickly + accurately is to review your own code first. Document why you made these particular changes. Explain why this counter-intuitive change was necessary. Explain why you made this tradeoff. And so-on.
It’s expensive to review someone else’s code - and you will get ahead further and faster if you make them as inexpensive for others to review as possible. Your teammates will appreciate this and so will you when the shoe is on the other foot.
On top of that though, you will often find errors in your own code when you go through the trouble of reviewing your own work - which will reduce the number of cycles it takes to successfully introduce a new change to the code base.
Get in Regular Communication
When I wrote the “Taxonomy of Terrible Programmers” (2013), you’ll notice that several of the terrible developer archetypes have one crucial bad habit in common:
- The Hoarder is a cautious creature, perpetually unsure of itself. The Hoarder lives in a world of perpetual cognitive dissonance: extremely proud of his work, but so unsure of himself that he won’t let anyone see it if it can be helped. So he hides his code. Carefully avoiding check-ins until the last possible minute, when he crams it all into one monolithic commit and hopes no one can trace the changes back to him. His greatest fear is the dreaded merge conflict, where the risk of exposure is greatest.
- The Island is the ultimate loner in the taxonomy of terrible software developers, as he desires above all things to be left in peace with his favorite text editor and devoid himself of all human contact. The ideal condition for the Island is one where communication with the outside world is kept at a minimum and strictly at his convenience. Just code, no humans.
- The Human Robot tries his best and his intentions are good. But he has a handicap: he interprets everything literally. The Human Robot is the world’s first true organic computer, which also means that every user-space detail of their work must be explained literally, byte-for-byte.
- The Stream of Consciousness programmer is related to the Illiterate in that he too cannot read code. However, what’s fundamentally different about the Stream of Consciousness is that he can’t read his own code in addition to that of every other developer on the team.
- The Agitator, like the Human Robot, is a social retard. But unlike the Human Robot, has no good intentions. An Agitator is not born, they are forged through years of suffering through undesirable work environments and programming assignments. Having been through shit work for years and years, the Agitator believes he or she now knows best and is determined to run things they see fit, whether they actually have the authority to or not. The goal of the Agitator is to establish dominance and control over their work environment through the use of force and intimidation.
The common bad behavior is poor or withheld communication. This problem isn’t unique to the software industry but it’s a much more visible issue in engineering organizations due to the precise and technical nature of our work, which gets disrupted when effective communication is absent.
Getting in effective, regular communication with your team is the greatest difference between a software developer who spins his or her wheels, wastes time, invents new problems, and pisses everyone else off in the process versus someone who actually gets things done.
No one is impressed with your ability to spend 40 hours rediscovering a problem someone else on your team painstakingly discovered and documented earlier this year. All you had to do was ask or look in the bug tracker. No one will fault you for not knowing the technical minutiae in a legacy code base - but everyone will think you’re an idiot for not asking about it before you spent hours and hours making major, incompatible changes to it that will have to be discarded or reverted.
Let’s distill “effective communication” into something tractable for software development teams - this is not an exhaustive list:
- “If you can’t draw it, you can’t explain it” - find a piece of diagramming software and get into the habit of using it regularly to express complex ideas. If you’re trying to modify a workflow in a legacy software system, but you can’t diagram how the current workflow works, then you don’t have enough information to begin your work. Diagramming software isn’t a panacea here either - use pen and paper to scratch up diagrams until you have a clear picture that you can share with others on your team.
- If you aren’t sure why something is the way it is, always ask - this is the lesson of Chesterton’s fence; if the fence exists for reasons that are not obvious to you (primary reasoning,) the original builder might have employed secondary reasoning. I.E. the reason why we have a cantankerous set of serialization functions is to allow customers to open files created with older versions of the software, which uses a different file format. Always try to get on the same page with the original builders before making changes.
- Document problems and ideas in writing - when you notice bugs, problems, inefficiencies, and sub-optimal experiences: document them! Capture the relevant details - the stack traces, the reproduction case, screenshots, and more. Putting all of this data into one place like your issue tracker (i.e. Github issues) will create artifacts that other members of your team can consume and share to improve the quality of your team’s software.
- Don’t make other people duplicate your effort (and vice-versa) - when communicating a bug don’t share the entire build / test log with your team and tell them “there’s a problem” - copy the relevant lines that prove the existence of the issue and share that, along with an optional link to the full build log. That will allow the other members of your team to cut to the chase and see what you see. That way no one else has to duplicate the work you just did. Also, the vice-versa is true: don’t duplicate other people’s work. For instance, you can cross-link to other people’s Github issues that are possibly related to your problem.
- Define a shared lexicon - one of the problems we often run into in technical projects is when members use different terms to refer to the same thing; so help your team standardize on a shared lexicon. I.e. are our customers called “customers” or “clients” inside our purchasing system? What’s the difference between a “product” and a “subscription”? This seems trivial but it makes a huge difference in how efficiently and precisely you can communicate. Create a shared lexicon, write it down, and add it to your documentation somewhere.
- Make fewer assumptions about others’ experience - the biggest communication pitfall I personally run into is when I assume what other people know before I speak. Get out of that habit and always ask “are you familiar with how _ system works?,” “have you worked with _ before?,” or “what’s your comfort level with _?” - and then calibrate your communication to that person’s level of experience relative to your own. This isn’t patronizing - it’s pragmatic. A beginner is going to want more of the big picture concepts explained so they can orient themselves accordingly; an experienced developer is going to want just the pertinent details so they can get to work quickly.
- Make it easy for others to scan your writing - the reason I’m using bulleted lists and bolded titles here is to make it easy for users who don’t want to read this post line-by-line to get take-home value quickly. Don’t be offended if people don’t read every line you painstakingly wrote - it’s not personal. Instead, anticipate and optimize for that - make use of lists, headers, bolding, and call-outs in your written text. This will help you get your point across efficiently even to speed-readers on your team.
- Use a blend of synchronous and asynchronous communication - developers quickly grow tired of endless meetings and they also hate being overwhelmed with email. So we have to find a happy medium and use a blend of both. It’s my preference to use asynchronous communication by default because it produces artifacts that can be referenced over and over again in the future, which makes the conversation “re-entrant.” However, that’s often not the best way to see the forest through the trees - a quick, organized kick off meeting usually gets the job done. Use the right tool for the job - don’t be afraid to ask for a meeting when you need it, but be mindful of the others’ time.
Use the Resources You Already Have
So you’re contributing to an open source project that already has:
- A public build system that retains logs for up to 30 days;
- An issue tracker with years’ worth of open and closed tickets;
- Documentation that explains how to build the project + run tests;
- A discussion board;
- A live chat that has dozens of active members at any given time; and most importantly
- All of the source code, including its commit history, is completely readable and even indexed for searching.
You submit a pull request that doesn’t pass the CI server, and you ping the maintainers asking why. You get ignored. Why?
In this case you didn’t use the resources you already have: the build logs and the test suite itself. All you had to do was click through and the build system will usually tell you what went wrong.
Alternatively, if this issue came up you could also search through the pull request / issue history and see if any other contributors have run into this type of trouble before.
It’s a good idea to get into communication often, as we mentioned above, but not when there’s a cheaper and faster route that doesn’t require another person’s time. Exhaust the simple options that, typically, don’t cost very much to try first and THEN bring the issue to the attention of other people on your team.
At the end of the day, working on software as a team sport really comes down to maximizing the utility of everyone’s time including your own. It’s cheaper for the entire team in aggregate for you to spend 10 minutes asking questions about how existing systems work (vs 40 hours learning it the hard way) and it’s also cheaper for you to spend 10 minutes digging through build server logs to try to answer your own question before bringing it up to someone else.
Discussion, links, and tweets
I'm the CTO and founder of Petabridge, where I'm making distributed programming for .NET developers easy by working on Akka.NET, Phobos, and more..
Tweet Follow @Aaronontheweb