The Future of AI Belongs to Experienced Operators with Good Taste
Not even AI can save the 'Idea Guys.'
- When Vibe Coding Goes Bad
- Knowing What Questions to Ask is 80% of the Battle
- LLMs Don’t Scale with Complexity, Baby
- Where LLMs May Succeed
I have a lot of respect for Geoffrey Huntley. So when I read his blog posts about AI over the past couple of months: “Dear Student: Yes, AI is here, you’re screwed unless you take action…” and “The future belongs to people who can just do things” among others, I thought to myself - “am I missing something?”
This image of his, in particular, summarizes his take on AI and the impact it’s going to have on the software development industry:

He’s essentially singing the same song that people who sell AI courses do: “if you’re not dropping everything to learn AI right now, you’re going to get left behind!” His conclusion to “The future belongs to people who can just do things” ends thusly:
Ya know that old saying ideas are cheap and execution is everything? Well it’s being flipped on its head by AI. Execution is now cheap. All that matters now is brand, distribution, ideas and [retraining] people who get it. The entire concept of time and delivery pace is different now.
Distribution, brand, et al are important - no doubt. The idea that any LLM, even ones with future capabilities, is a catch-all substitute for experience is laughable.
In a world where typing in the right prompt to a chat window is “all you need” for “execution,” this actually makes idea guys even more commodified and worthless than they already are - and they’re already worthless.
When Vibe Coding Goes Bad
The term “vibe coding” was coined earlier this year by Andrej Karpathy, the former head of AI for Tesla.
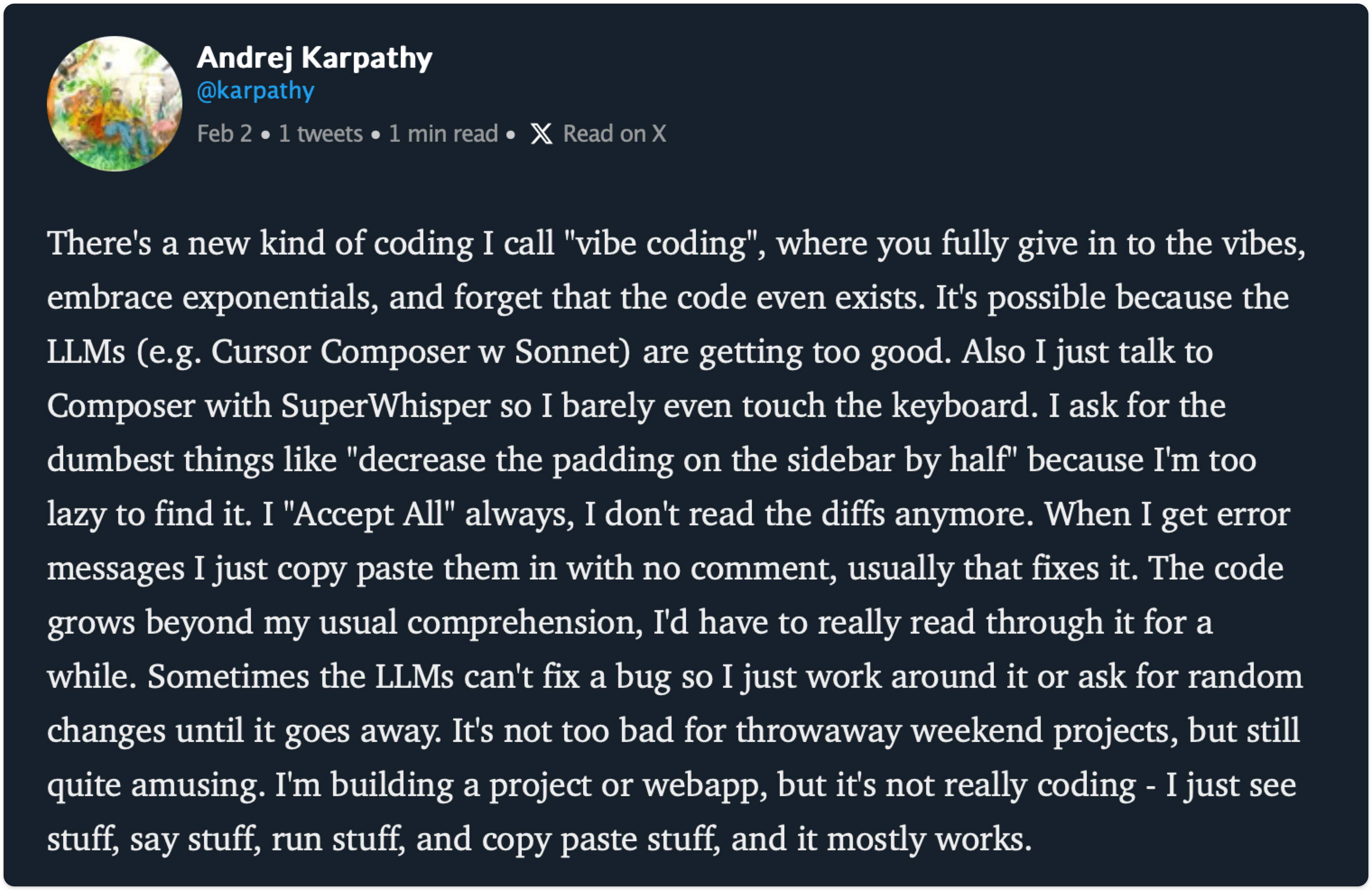
The original meaning as I understand it:
“Vibe coding is: in the hands of an experienced coder, simply asking for what you want and letting the AI do its thing - because the consequences of the AI ‘doing it wrong’ are minimal in this context.”
This was also kind of meant in jest - working on CSS on a fun side project, not writing secure payments code for an eShop.
Unfortunately “vibe coding” has now been conflated to mean carrot-topped zoomers with no coding experience shitting out single-person SaaS companies without understanding how their products work.
Hilarity ensues:
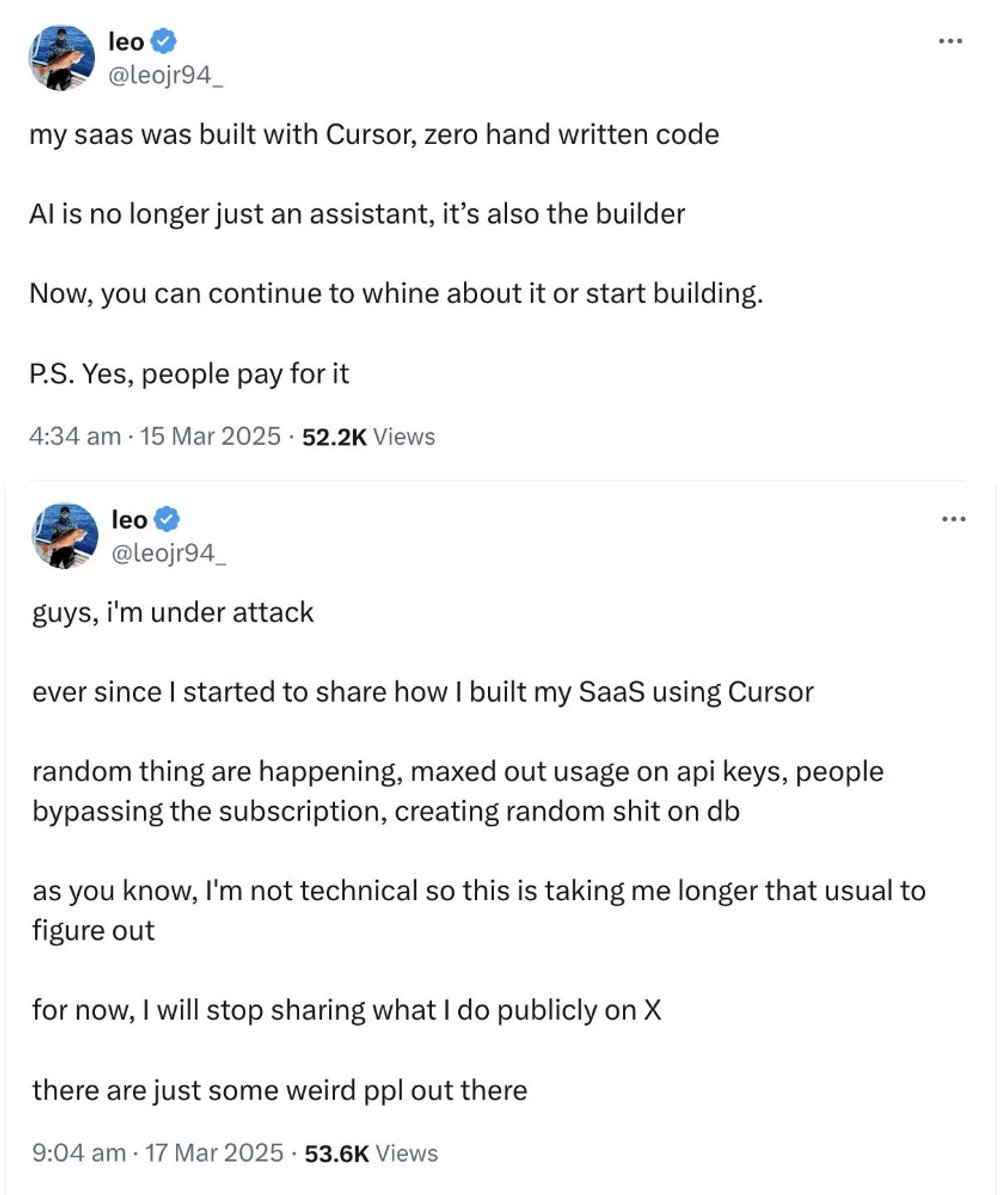
Oops. Guess he should have included “don’t make any mistakes and don’t let me get hacked” in his prompts somewhere. There are hundreds of examples like this running around on Twitter right now.
LLMs like Claude et al are trained on the entire corpus of the Internet, with many tens of thousands of pages written about the secure storage of API keys, and still managed to embed them in plain text in JavaScript. An experienced web developer looking carefully at Cursor’s output would have spotted that and could have either fixed it or prompted the AI to.
But if you’re completely trusting the AI to commodify your execution, this is your just desserts.
Knowing What Questions to Ask is 80% of the Battle
I’m a huge fan of Cursor. I’ve compiled a very detailed set of Cursor rules for .NET and I’ve used it for my systems programming in .NET along with lots of other areas where I have less experience.
The AI-powered creations I’m most proud are the animations for our “Why Learn Akka.NET?” video:
You can view the raw animations here: https://petabridge.com/bootcamp/visualizations/
These were all built by Cursor using libraries like Three.js. I spend most of my time writing low-level systems code for .NET - I know very little about 3D animation and a passable amount of JavaScript / CSS. These is zero chance I could write something like this from scratch without spending hundreds of hours learning how.
By leveraging Cursor and Claude Sonnet 3.5 under the covers, I animated my ideas into acceptable shape after about 45 hours and at a cost of ~$25.
Had I worked with a real human animator to put all of this together it would have taken me thousands of dollars, at least as many of my own hours, and months of back and forth before going live onto our YouTube channel. The latter is the real factor that drove me to try my hand at using AI to do this - getting the project done now.
Producing all of these animations still took 45 hours - how so? Because Cursor’s technical execution wasn’t quite up to snuff; its output was brittle; and thus I had to intervene and apply my own software engineering in order to succeed.
Some examples of what it did wrong:
-
Every visible element was scaled and positioned using absolute coordinates - this meant that if I prompted something like “make the phone 50% bigger” the entire scene would fall apart.
I had to steer Cursor towards using object-oriented representations of each object in each scene using a combination of relative positioning (i.e. the text on the phone screen gets positioned relative to the phone) and sizing based off of a scalar value - adjust the scalar and the entire set of nested objects should scale relatively.
-
Every visible element was animated and sequenced individually - this would produce an epileptic-seizure-inducing animation where everything would pop off at once during a scene transition, like the fireworks going off all at once during San Diego’s 2012 4th of July celebration. Again, I had to push Cursor to apply a bit of OOP to its design here: group the elements together and apply the animation starting from the outer-most objects. This resulted in a smooth animation like we’d expect.
-
Showing the wrong “side” of 3D objects - one of the biggest head-scratchers I had, until I realized that Three.js was literally creating a 3D rendering of my shape, was that Cursor had the computer monitor in one of my animations displayed to me backwards: I was seeing the back of the monitor where none of the UI animations were actually occurring. I had to ask it to flip the rendering 180 degrees so we could see the front of it. It did this several times.
-
Frequently deleted elements by accident during edits and revisions - one thing I noticed on both this project and many simpler ones is that Claude and ChatGPT models will frequently truncate or delete unrelated content outright, seemingly by accident, during editing. I had to keep a very careful eye and commit to source control aggressively to mitigate this.
-
Fixed scheduling for transitions and phases - this wasn’t really a design mistake the Cursor made, but an example of where it was really useful for me to weigh in.
I needed some control over how densely some animations were packed and how quickly they’d transition between scenes - because I wasn’t quite sure how long it would take me to read my lines in the voice-over. Much better to have that control by re-shooting the animation with an adjusted transition interval versus trying to use DaVinci Resolve editing magic.
I didn’t need direct experience in understanding the intricacies of 3D animation to be successful with this project. I couldn’t tell you the first thing about writing a shader or whatever.
But I did need to have enough programming experience to understand how the LLM was erring and to suggest how to fix it.
Telling Cursor over and over again “no, you made the shapes the wrong size” won’t get you anywhere - you have to go a level deeper.
Knowing what questions to ask and what guidance to give in return is essential to getting good outcomes with LLMs. That comes with experience - knowing what you’re seeing because you recognize the pattern, even if you’re not 100% current on the syntax.
LLMs Don’t Scale with Complexity, Baby
There were several cases in my animation project where Claude’s context windows would become unusable - usually after exceeding ~32k tokens. That’d require usually capturing our original prompt + some of the learnings we made along the way into a new prompt and starting over.
This is a problem the AI industry hasn’t cracked and probably won’t crack without significant departures from the current LLM formulae - long context windows simply don’t work due to the Curse of dimensionality.
Once you get beyond a certain window size you’re working with extremely sparse regions of trained memory and the efficacy of returned answers plummets1:
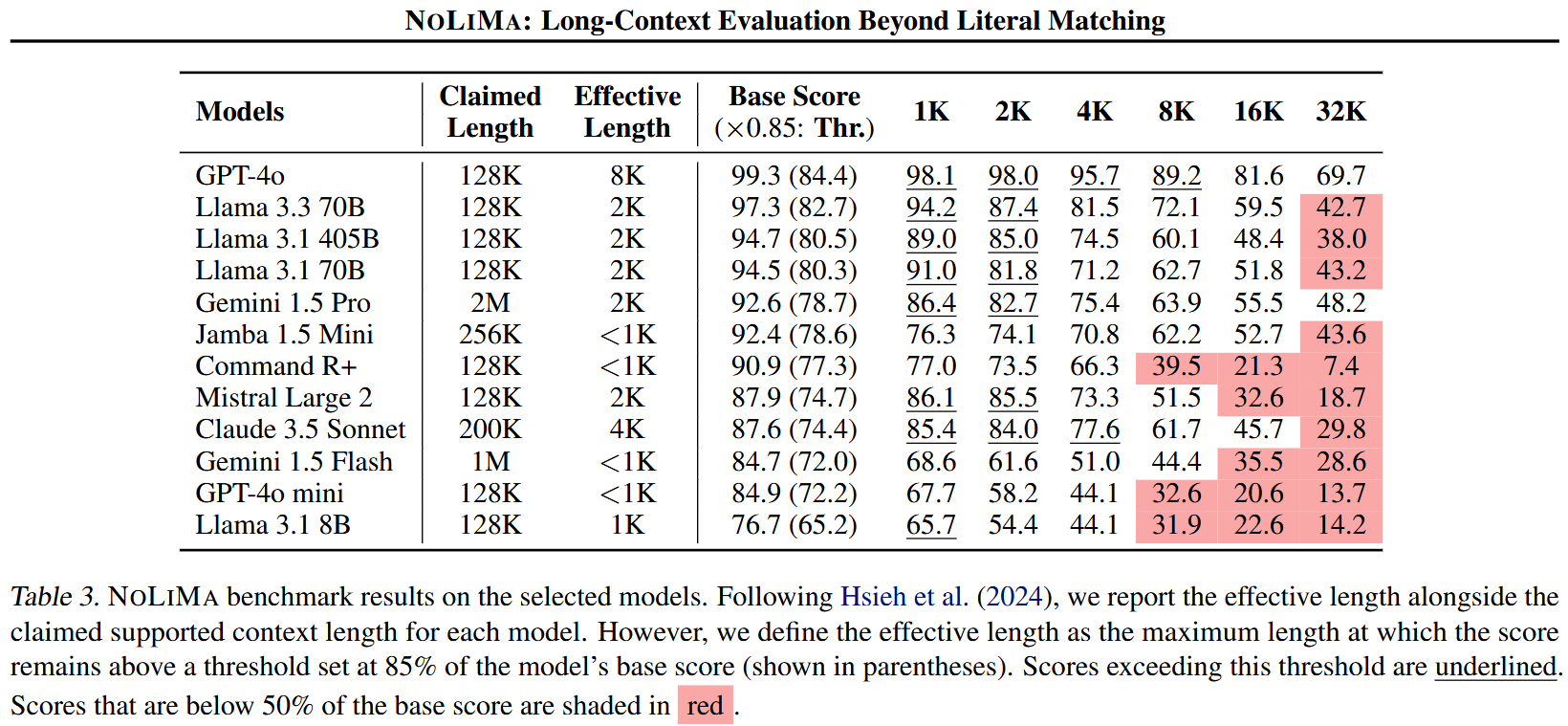
And this doesn’t even touch other issues that remain unresolved with LLMs: hallucinations, basic math errors, and just non-determinism in general.
So much talk about AI coding tools, vibe coding, AI agents
— Gergely Orosz (@GergelyOrosz) March 24, 2025
So many complaints of these tools “breaking down” above some complexity / context length
So little - basically no - talk about software architecture that makes for code devs can easily maintain/evolve. Or AI tools!
Well, well, if it isn’t my hobby horse - high-optionality programming. Gergely’s post begs the question: why don’t AI agents design their own code to be maintainable for themselves in the future?
Probably the same reason most human software developers can’t do it either: this is a matter of experience and taste.
Designing a system with maintainability in mind requires foresight, planning, and sustained effort + enforcement. LLMs inherently can’t do any of these three things.
You can’t just write into a prompt “make this maintainable into the future.” You can’t even write down something more specific like “use event-sourcing with separate projected read-models” and expect it to work. System prompts are not the word of God.
Cursor rules files are at best, mild suggestions to the LLM with examples and counter-examples. There is zero guarantee that they will be followed, applied consistently, and definitely not “understood” in any meaningful sense. Non-determinism is still the rule.
Instead at each stage of software development an operator is going to have to ensure that these things happen, even if all of the code generation itself is delegated to the LLM. All AI applications, at some level, are designed to hide the non-determinism through layers of validation and steering - someone’s going to have to do that, and it’s probably not going to be Mr. Idea Guy.
Where LLMs May Succeed
There are many grifters selling courses on leveraging AI for success and very few people actually doing it2. In terms of where real operators are having some success with LLM-powered applications in the market, I think Phillip Carter said it best:
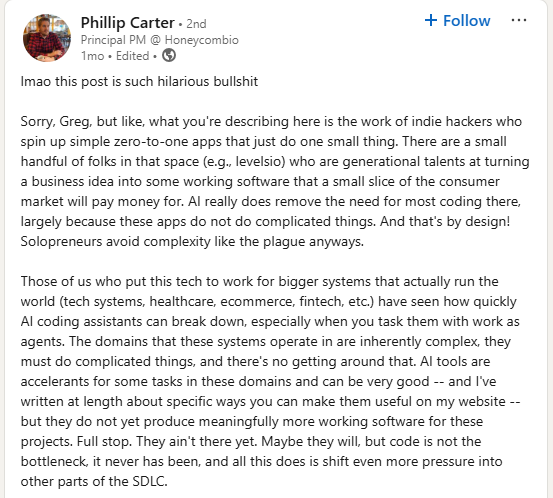
The reason we haven’t seen very many 100% AI-coded applications succeed commercially is because, well, actually commodifying the “execution” as Geoffrey put it, encompasses much, much more than merely typing code. Beyond that though, LLMs can’t even do 100% of the coding reliably. This is also why, despite Anthropic’s CEO predictions that “AI will take over most software engineering jobs in 12 months” they still have 70+ software engineering roles open.
I’ve mentioned the Curse of dimensionality already as one reason why LLM efficacy drops off once context windows get too large - another idea worth observing here is Gall’s law:
A complex system that works has evolved from a simple system that worked. A complex system built from scratch won’t work. - John Gall
LLMs have yet to cross the tremendous complexity chasm that stands between them and replacing the work of real software engineers working on the projects that run the world. The transformer model will likely never get there.
Getting a group of retarded 32k-token-max LLMs to autonomously produce a FinCEN-complaint global payments network is the Infinite monkey theorem but for people whose greatest aspiration is to become a TedX speaker.
The blinkered advocates of AI will refer skeptics to the following chart:
graph TD
A["This problem is too complicated"]
B["AI scaling solves this"]
A --> B
B --> A
Along with some mumbling about how I don’t understand exponential scaling. This is Underpants Gnome-level cope uttered by people who couldn’t achieve anything before AI and won’t achieve anything afterwards, hence why they’re busy selling courses on AI and scaring people about falling behind instead living off passive income from AI applications themselves.
When it comes to generative AI, the future belongs to experienced operators with good taste.
-
Notably, none of the people selling AI courses themselves appear to have launched any successful applications with it, despite having good distribution. ↩
Discussion, links, and tweets
I'm the CTO and founder of Petabridge, where I'm making distributed programming for .NET developers easy by working on Akka.NET, Phobos, and more..
Tweet Follow @Aaronontheweb