Stop Failing The `git clone && run` Test
Automating local development orchestration pays big dividends.
I’ve done a ton of consulting as part of my work at Petabridge over the past 10 years and I run into developer onboarding problems constantly with new clients. It takes much longer than it should to clone a customer’s application from source control and successfully run it.
Continuous deployment and continuous integration (CI/CD) get a ton of attention in the DevOps space, but improving the “first run” experience for onboarding new team members is rarely mentioned in these spaces. A strong “first run” experience just as important and an essential ingredient to good CI/CD outcomes.
Bad “First Run” Experiences
If your “first run” experience is agonizing, this means your local development feedback loop is broken too even for experienced members of your team.
For instance, if I want to make a SQL schema change and test it, how easy is it for me to:
- Actually do that, in a local environment;
- Revert that change / change it again if I’m unhappy with it; and
- Verify that my change was safe or otherwise acceptable?
If your applications’ first run experience is any more complicated than git clone && run1 then you have room to improve.
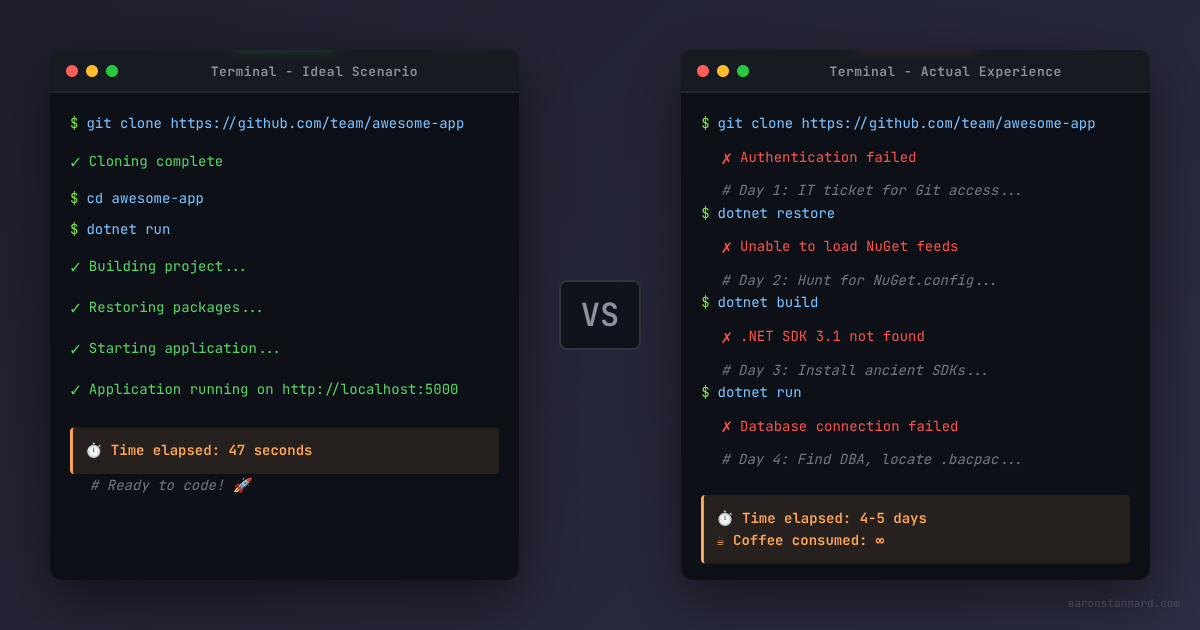
Bad for Onboarding
When I start a new consulting project with a customer, my experience isn’t all that different from a new developer joining their team.
It usually goes like this:
- Get access to customer’s repository, try to
git cloneit; often fails due to some combination of conflicting authorization rules but for the sake of argument let’s say it works out of the box. - Try to build repository - fails due to missing proprietary package feeds; have to go back to IT department to get access to those. 1-2 days of time lost here.
- Finally get access to feeds - try to compile; packages get restored but there’s some other obscure missing dependency I didn’t know I needed, like an absolutely ancient CVE’d to hell-and-back version of the .NET Framework. Lose half a day working my way through that.
- Application compiles - but can’t launch due to dependencies on missing databases and external services. In extremely rare cases, someone has written a
docker-compose.ymlfile that hasn’t been updated in five years - and this might host local copies of Postgres, Grafana, or whatever. Sometimes works if I can find the totally undocumented configuration block that allows me to tell the application to use these. - Application launches, hits the Dockerized local database instance, but all of the schema and required seed data is missing. Now we have a real problem - there’s no standard way to create a local instance of the shared development environment database because… That’s not a thing the development team, which doesn’t hire people often, has decided to standardize. Agony ensues and after cajoling the DBA to give me a
.bacpacfile from the QA / UAT / DEV environment, I can finally get something reasonable-ish up and running. - Each time I experiment with a schema change or anything else that touches the database, reverting that experiment is costly and time-expensive.

A bad first run experience creates lots of onboarding friction and lengthens the learning curve significantly for new-comers.
Really Bad for Testing
Bad first run experiences are a sign of sloppiness in your team. If no one takes the time to automate spinning up a runnable environment from git clone, then it’s very unlikely that your application has any sort of meaningful test coverage either.
If we’re unit testing our application with n dependency-injected mocks at every turn, we’re not actually testing how all of these features interact with each other in real life. The useful data signals they provide are pretty limited.
Running a set of comprehensive integration tests, such as an end-to-end service or HTTP API invocation, gives you the ability to see and touch what happens when all of the layers get hit.
You don’t necessarily want to design 100% of your tests to function this way (unit tests still have value,) but by not automating the first run experience then you don’t have a robust way of doing integration testing at all.
At best, you can test your application against a set of shared database instances and hope that per-run invocations don’t create data contamination or other cross-pollination effects.
The gold standard here is git clone && run - you should be able to get a local, isolated replica of everything you need to run and test your application locally through this alone.
Bad for Veterans
Lastly, bad first run experiences mean slower iteration speeds and feedback loops for the developers on your team.
I’ve been using .NET Aspire, which allows even fairly complicated applications to have an excellent first run experience.
The biggest issue it solves for me is it makes it very easy for me to tear down my previous test database, re-seed it with schema and data, and then run either integration tests or manual click testing while I’m still in the middle of vibing out changes I want to make to Sdkbin.
The process that .NET Aspire automated away involved spinning up dependencies via docker compose, running some dotnet ef commands to apply schema changes, and then running a manual executable to apply data migrations. This process took tens of minutes each time before - now all I have to do is just run dotnet run on my Aspire application2.
By the way - that manual process is still orders of magnitude better than what most enterprise developers endure daily on their jobs. So as an industry, we have work to do.
How to Have a Great First Run Experience
So if you read this article and decided that it’s time to invest in automating a good first run experience for your applications, where would you begin?
- Prefer monorepos - there are lots of cases where human/organizational boundaries are going to make monorepos untenable, but they are the ideal for great first-run experiences. Having everything checked into a single repository makes it much easier to orchestrate and run all of the dependencies that compose your application in the first place.
- Leverage containers - if you can’t use a monorepo, then having each team that builds a service ship their output to a privately hosted Docker container registry is probably the next best thing. That way each application that needs a good first run experience can pull the dependencies and launch them using an orchestration tool like .NET Aspire or
docker compose. - Automate schema migration and seed data population - this is a special case for containerizing dependencies, but nowhere is this more important than the database dependencies that applications need. Inside your application you should maintain an artifact - either an executable or a Docker container - the can idempotently populate a fully functioning local instance of your application’s schema and relevant test data. User accounts and other entities can have hard-coded values - that’s actually fine and likely makes testing easier.
- Use Testcontainers - if your schema can be containerized or applied to a container running the appropriate database easily, then the next obvious step is to begin using Testcontainers—a testing library that provisions Docker containers on-demand during test execution—to run your application’s tests with its real dependencies. This will help you find real problems much more quickly than trying to use fakes or mocks.
- Prefer implicit authentication for development dependencies - where possible, make it as easy as possible to implicitly authenticate a developer’s access to resources like internal artifact feeds or container registries. For instance, if you’re using Microsoft Entra for domain authentication then you can use Entra policies to authenticate user access to Azure DevOps artifact feeds. Thus, once the developer logs into their machine they should already (theoretically) be credentialed to install the internal packages or container images they need to
git clone && runsuccessfully. This is probably the hardest of all the steps to do correctly and consistently, but you’ll need to figure it out in order to get CI/CD to work anyway - so you might as well make it easier for human users too.
If you can get to a stage where git clone && run is doable with your applications, you will start to see improvement in other areas too - such as test coverage, CI/CD automation quality, and developer productivity. Make the time to do it.
Getting Started
Don’t try to implement all five recommendations at once. Here’s a pragmatic approach:
- Document your current state - Time how long it takes a new developer to get running from
git cloneto first successful build and run. List the speed bumps that occur. - Pick the biggest pain point - Usually this is database dependencies or authentication issues.
- Start with containers - Containerizing dependencies (#2) and using Testcontainers (#4) give you the fastest return on investment.
- Automate incrementally - Each small improvement compounds over time.
Track your progress by timing the “clone to running” journey quarterly. When you get it under 5 minutes, celebrate—you’ve achieved something most enterprise teams never do.
Discussion, links, and tweets
I'm the CTO and founder of Petabridge, where I'm making distributed programming for .NET developers easy by working on Akka.NET, Phobos, and more..
Tweet Follow @Aaronontheweb