Your HTML Comments Are More Powerful Than You Think: Building Custom Validation Grammars with HtmlAgilityPack
How to implement inline HTML comment-based validation control using HtmlAgilityPack - because config files are a pain
- Links That Will Never Validate
- Implementation with HtmlAgilityPack
- Testing the Edge Cases
- Real-World Usage
- The Single Source of Truth Principle
- Building Tools the .NET Ecosystem Needs
- Try It Out
We were getting ready to redesign and simplify phobos.petabridge.com - our Akka.NET observability platform documentation site. The plan was to remove a bunch of old pages, restructure the information architecture, and redirect everything properly so we wouldn’t break any inbound links from Google, Stack Overflow, or the blog posts referencing our documentation.
The problem: how do we know we’re not blowing up external links during this restructuring? We needed full, measurable, observable control over the sitemap as we made changes. Every redirect had to work. Every removed page needed a destination. One broken link could cost us traffic and credibility. At its core, this is a continuous integration problem.
So I built LinkValidator - a CLI tool to validate all internal and external links in our statically generated sites during CI/CD on Azure DevOps and GitHub Actions.
The goal: fail the build if we break anything. Crawl the site, validate every link, and catch problems before they reach production.
Then I hit an immediate problem.
Our documentation has links to localhost resources - Grafana dashboards at http://localhost:3000, Prometheus at http://localhost:9090, Jaeger tracing at http://localhost:16686. These are part of our observability stack demos. They’re 100% correct when someone’s running the demo locally, but they fail validation every time in CI because there’s no Grafana instance running on a GitHub Actions runner.
I needed a way to selectively suppress link validation, and I wanted it to be contextual - right there in the HTML where the “broken” link lives, not buried in some global configuration file that’s completely divorced from the context of the page itself.
Here’s how I built that in C# using HtmlAgilityPack and a little sprinkling of Akka.NET.
Links That Will Never Validate
When you’re documenting distributed systems or microservices architectures, you inevitably end up with documentation that looks like this:
## Observability Stack
Once you've started the demo, you can access:
- [Grafana Dashboard](http://localhost:3000) - metrics visualization
- [Jaeger UI](http://localhost:16686) - distributed tracing
- [Prometheus](http://localhost:9090) - metrics collection
Every one of those links points to localhost on a specific port. They’re 100% correct when someone is running the demo, but they’ll fail validation every single time in CI because, well, there’s no Grafana running on the build agent.
You know what happens next. Your CI build fails. Again. You check the logs. “Failed to validate http://localhost:3000” - no kidding, there’s no Grafana running on your GitHub Actions runner. You start ignoring validation errors and move on.
Until, eventually, a real bug creeps in and you miss it because you’ve gotten into the habit of disregarding LinkValidator output as noise. That’s… not great.
So, Configuration Files Then?
The traditional solution? Maintain a configuration file with URL patterns to ignore:
{
"ignorePatterns": [
"http://localhost:*",
"http://127.0.0.1:*"
]
}
This works, but it’s terrible from a maintainability perspective. You’re managing link exceptions in a completely different place from where the links actually live. Six months later, someone updates the docs and has no idea why certain links aren’t being validated. A year later, your config file has 47 ignore patterns and nobody remembers what half of them are for.
It’s a context problem - the ignored routes are done so globally, divorced from any page-specific context. And this also means the solution is somewhat brittle - what if someone really does include a wrong / accidental localhost link1 at some point in the future? That’ll also get ignored. Oops.
The Solution: Inline HTML Comments
We needed a more contextual way of expressing what is and isn’t a real broken link.
My inspiration came from our own Akka.NET documentation. We use markdown linting tools that support inline HTML comments to suppress specific rules when contextually appropriate. For instance, we embed YouTube videos in our docs using <iframe> tags - something that can’t be expressed in valid Markdown. We use <!-- markdownlint-disable --> comments around those sections to suppress the linting rules, then restore normal validation afterwards.
It worked beautifully for that use case. Why not use the same pattern for link validation?
LinkValidator now supports two patterns:
Ignore a single link:
<!-- link-validator-ignore -->
<a href="http://localhost:3000">This link will be ignored</a>
<a href="http://localhost:9090">This link will be validated</a>
Ignore a block of links:
<!-- begin link-validator-ignore -->
<div>
<p>These local development links won't be validated:</p>
<a href="http://localhost:3000">Grafana Dashboard</a>
<a href="http://localhost:16686">Jaeger UI</a>
<a href="http://localhost:9090">Prometheus</a>
</div>
<!-- end link-validator-ignore -->
The comments are case-insensitive (<!-- LINK-VALIDATOR-IGNORE --> works too), and they give you precise, contextual control over what gets validated.
Implementation with HtmlAgilityPack
I want to walk through the implementation because it demonstrates something important: building developer-friendly features doesn’t have to be complicated. The entire ignore comment system is maybe 100 lines of code, and most of that is handling edge cases.
Here’s what made this particularly satisfying to build: it was really easy to implement using HtmlAgilityPack.
The core parsing logic in LinkValidator looks like this:
public static IReadOnlyList<(AbsoluteUri uri, LinkType type)> ParseLinks(string html, AbsoluteUri baseUrl)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
IReadOnlyList<(AbsoluteUri uri, LinkType type)> links = doc.DocumentNode
.SelectNodes("//a[@href]")?
.Where(node => !IsLinkIgnored(node)) // <-- The magic happens here
.Select(node => node.GetAttributeValue("href", ""))
.Where(href => !string.IsNullOrEmpty(href) && CanMakeAbsoluteHttpUri(baseUrl, href))
.Select(x => ToAbsoluteUri(baseUrl, x))
.Select(x => (x, AbsoluteUriIsInDomain(baseUrl, x) ? LinkType.Internal : LinkType.External))
.Distinct() // filter duplicates - we're counting urls, not individual links
.ToArray() ?? [];
return links;
}
The key is the .Where(node => !IsLinkIgnored(node)) filter. This is where we check both for standalone ignore comments and ignore blocks.
Detecting Standalone Ignore Comments
For <!-- link-validator-ignore --> comments, we need to look at the link’s previous siblings:
private static bool IsLinkIgnored(HtmlNode linkNode)
{
// Check if link is within an ignore block (we'll get to this)
if (IsWithinIgnoreBlock(linkNode))
return true;
// Check if previous sibling is an ignore-next comment
var previousNode = linkNode.PreviousSibling;
while (previousNode != null)
{
if (previousNode.NodeType == HtmlNodeType.Comment)
{
var commentNode = (HtmlCommentNode)previousNode;
var commentText = commentNode.Comment.Trim();
// Remove comment delimiters and trim
commentText = commentText.Replace("<!--", "").Replace("-->", "").Trim();
// Check for standalone ignore (not "begin")
if (commentText.Equals("link-validator-ignore", StringComparison.OrdinalIgnoreCase))
return true;
}
else if (previousNode.NodeType == HtmlNodeType.Element)
{
// Stop looking if we hit another element
break;
}
previousNode = previousNode.PreviousSibling;
}
return false;
}
This walks backwards through the link’s siblings until we either find a matching comment or hit another HTML element.
The key insight here is that HtmlAgilityPack gives you a real DOM tree to work with. We’re not doing regex parsing or string manipulation - we’re walking nodes and checking their relationships. This is exactly the kind of problem XPath was designed to solve.
Detecting Ignore Blocks
For block-level ignoring, we need to walk up the DOM tree and check if we’re inside an ignore block at any level:
private static bool IsWithinIgnoreBlock(HtmlNode node)
{
var current = node;
while (current != null)
{
// Check if there's an ignore block at this level
if (current.ParentNode != null)
{
var siblings = current.ParentNode.ChildNodes;
var inIgnoreBlock = false;
foreach (var sibling in siblings)
{
// Check for comment nodes
if (sibling.NodeType == HtmlNodeType.Comment)
{
var commentNode = (HtmlCommentNode)sibling;
var commentText = commentNode.Comment.Trim();
commentText = commentText.Replace("<!--", "").Replace("-->", "").Trim();
if (commentText.Equals("begin link-validator-ignore", StringComparison.OrdinalIgnoreCase))
{
inIgnoreBlock = true;
}
else if (commentText.Equals("end link-validator-ignore", StringComparison.OrdinalIgnoreCase))
{
inIgnoreBlock = false;
}
}
// If we've reached the current node and we're in an ignore block, return true
if ((sibling == current || sibling.Descendants().Contains(node)) && inIgnoreBlock)
{
return true;
}
}
}
current = current.ParentNode;
}
return false;
}
This traverses up the DOM tree, checking at each level whether we’re inside an active ignore block. The state machine tracks begin and end comments to determine if the link falls within an ignored region.
Testing the Edge Cases
Now here’s where things get interesting. This feature is deceptively simple to describe but has a surprising number of edge cases. What if someone puts two ignore comments in a row? What if ignore blocks are nested? What if there’s whitespace between the comment and the link?
I don’t want other developers on my team griping about the validator not working and I personally don’t want to be inconvenienced by bugs like this when I’m working on other projects. Thus, it’s best to test weird corner cases at the onset:
[Fact]
public void Should_only_ignore_next_immediate_link()
{
var html = @"
<html>
<body>
<!-- link-validator-ignore -->
<a href=""http://localhost:3000"">Ignored Link</a>
<a href=""http://localhost:9090"">Not Ignored</a>
<a href=""https://www.google.com"">Normal Link</a>
</body>
</html>";
var links = ParseHelpers.ParseLinks(html, _baseUrl);
links.Should().HaveCount(2);
links.Should().Contain(x => x.uri.Value.ToString().Contains("localhost:9090"));
links.Should().Contain(x => x.uri.Value.Host == "www.google.com");
links.Should().NotContain(x => x.uri.Value.ToString().Contains("localhost:3000"));
}
[Fact]
public void Should_handle_multiple_ignore_blocks()
{
var html = @"
<html>
<body>
<a href=""https://www.google.com"">Normal Link 1</a>
<!-- begin link-validator-ignore -->
<a href=""http://localhost:3000"">Ignored Link 1</a>
<!-- end link-validator-ignore -->
<a href=""https://www.github.com"">Normal Link 2</a>
<!-- begin link-validator-ignore -->
<a href=""http://localhost:9090"">Ignored Link 2</a>
<!-- end link-validator-ignore -->
<a href=""https://www.stackoverflow.com"">Normal Link 3</a>
</body>
</html>";
var links = ParseHelpers.ParseLinks(html, _baseUrl);
links.Should().HaveCount(3);
links.Should().Contain(x => x.uri.Value.Host == "www.google.com");
links.Should().Contain(x => x.uri.Value.Host == "www.github.com");
links.Should().Contain(x => x.uri.Value.Host == "www.stackoverflow.com");
links.Should().NotContain(x => x.uri.Value.Host == "localhost");
}
Edge cases matter. What happens with nested blocks? Multiple ignore comments in a row? Case sensitivity? All of this needs to work predictably, or developers will lose trust in the tool.
Real-World Usage
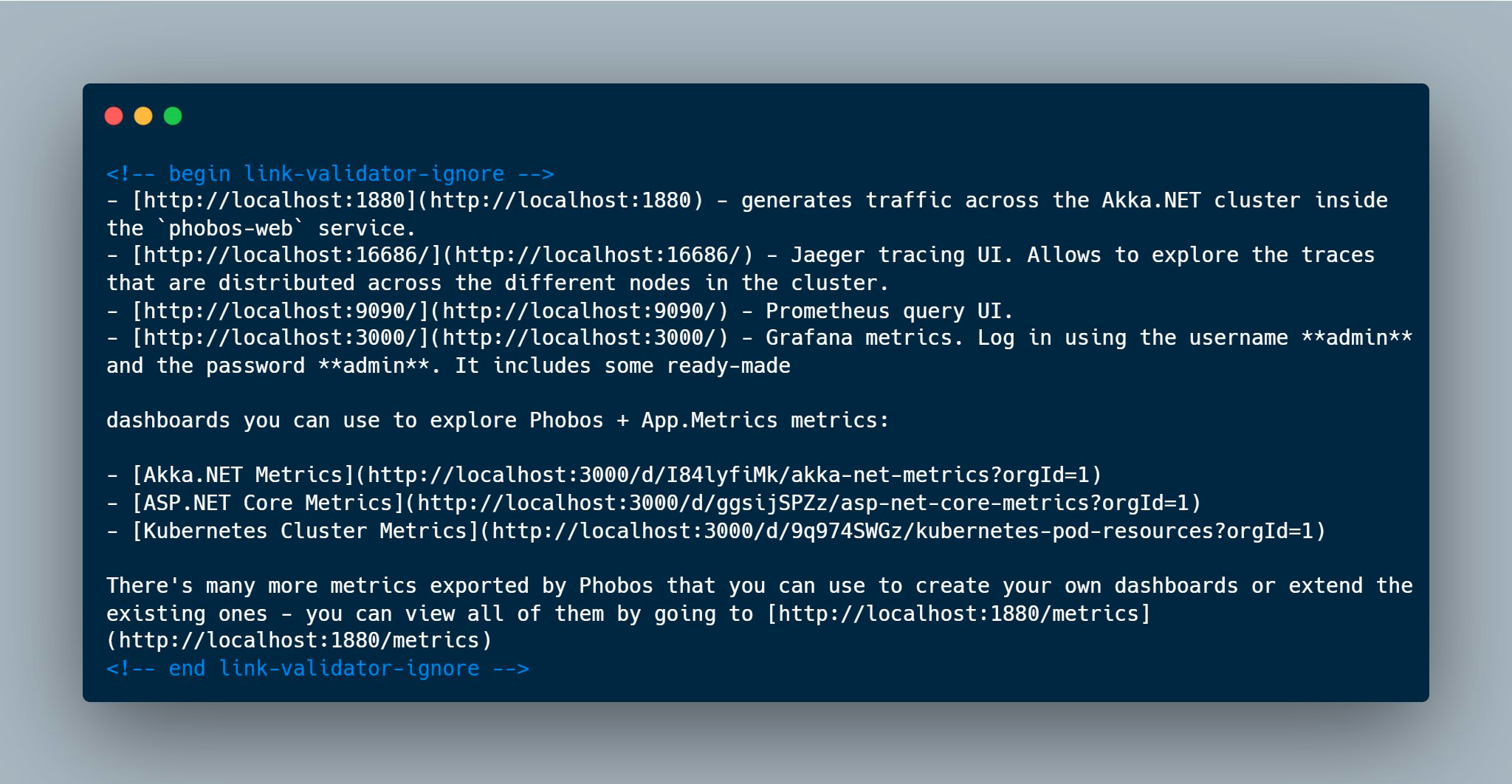
This feature has already saved us from several CI build failures. Here’s how it looks in actual Phobos documentation:
<!-- begin link-validator-ignore -->
- [http://localhost:1880](http://localhost:1880) - generates traffic across the Akka.NET cluster
- [http://localhost:16686/](http://localhost:16686/) - Jaeger tracing UI
- [http://localhost:9090/](http://localhost:9090/) - Prometheus query UI
- [http://localhost:3000/](http://localhost:3000/) - Grafana metrics dashboard
<!-- end link-validator-ignore -->
When LinkValidator crawls the docs site in CI, it skips these links entirely. No false failures, no need to maintain a separate config file, and the intent is crystal clear to anyone reading the documentation.
The Numbers
We’ve deployed this in the Phobos documentation pipeline where it validates approximately 150+ pages and 2,000+ links on every PR. The entire validation - crawling, parsing, and checking every link - completes in under 30 seconds thanks to Akka.NET actors handling concurrent crawling.
Zero false positives from localhost links. Zero “oh crap, I forgot to update the ignore config” moments. The feature just works, which is exactly what you want from a CI tool.
The Single Source of Truth Principle
From a developer tools perspective, you want to maintain a single source of truth for your context. The markdown and HTML documents are that source of truth. Everything else - configuration files, build scripts, deployment manifests - should derive from that primary source with minimal additional configuration.
When you divorce validation rules from their context and scatter them across external config files, that can become a future source of technical debt and forgotten lore in your code base. Developers have to mentally map between the config file and the actual content, keeping two separate models in their head simultaneously. That’s exhausting and potentially error-prone.
Using comment-based grammar gives you an additional layer of metadata right where you need it. The validation rules live alongside the content they’re validating. The context is immediately obvious. There’s one place to look, one place to update, one source of truth.
This is exactly how professional markdown linting tools work, and it’s proven to be the right approach for managing exceptions and special cases inline.
Building Tools the .NET Ecosystem Needs
Here’s what made this project gratifying: the .NET ecosystem doesn’t really have tools like this compared to npm. JavaScript developers have been shipping sophisticated CLI tools for web development for over a decade. Meanwhile, .NET developers often reach for Node.js tools even when working on .NET projects.
I wanted to demonstrate that you can build NPM-style CLI tools for web development work in .NET. The ecosystem has matured tremendously - between System.CommandLine for CLI parsing, HtmlAgilityPack for HTML processing, and Akka.NET for concurrency, you can ship a professional-grade tool in a weekend.
I also knew that Akka.NET happened to be a really good tool for this type of parallel processing. Being able to crawl hundreds of pages concurrently while managing state and coordination through actors made this implementation significantly simpler than it would have been with raw threading or Task-based parallelism.
But what separates a tool people tolerate from one they want to use is the developer experience. Inline HTML comments for validation control is a tiny feature, but it makes LinkValidator significantly more pleasant to work with. It respects the developer’s time and mental model - the configuration lives where the problem is, not in some distant YAML file.
That’s the kind of attention to detail that matters when you’re building tools for developers. We’re a picky bunch, and rightfully so. Our tools should be as thoughtfully designed as the applications we build with them.
Try It Out
If you’re validating links in your CI/CD pipeline (or thinking about it), give LinkValidator a try. It’s open source, cross-platform, and designed to make broken links a thing of the past.
And if you’re building your own developer tools - whether it’s a CLI, a library, or a full platform - remember this: the features that separate “tolerable” tools from “indispensable” ones are usually the small ones. The inline comments. The sensible defaults. The things that respect the developer’s time and mental model.
We’re a picky bunch, and rightfully so. Our tools should be as thoughtfully designed as the applications we build with them.
What’s Next
I plan to ship LinkValidator as an AOT native binary once we make more progress on Akka.NET 1.6’s native AOT support. Right now it requires the .NET runtime, but a self-contained executable with zero dependencies would make deployment even smoother.
Discussion, links, and tweets
I'm the CTO and founder of Petabridge, where I'm making distributed programming for .NET developers easy by working on Akka.NET, Phobos, and more..
Tweet Follow @Aaronontheweb