Cassandra, Hive, and Hadoop: How We Picked Our Analytics Stack
This is an archive of a blog post I wrote for the MarkedUp Analytics blog on February 19th, 2013. It’s been a popular post and I’m posting it here in order to preserve it.
When we first made MarkedUp Analytics available on an invite-only basis to back in September we had no idea how quickly the service would be adopted. By the time we completely opened MarkedUp to the public in December, our business was going gangbusters.
But we ran into a massive problem by the end of November: it was clear that RavenDB, our chosen database while we were prototyping our service, wasn’t going to be able to keep growing with us.
So we had to find an alternative database and data analysis system, quickly!
The Nature of Analytic Data
The first place we started was by thinking about our data, now that we were moving out of the “validation” and into the “scaling” phase of our business.
Analytics is a weird business when it comes to read / write characteristics and data access patterns.
In most CRUD applications, mobile apps, and e-commerce software you tend to see read / write characteristics like this:
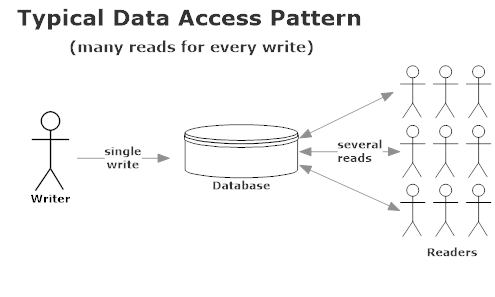
This isn’t a controversial opinion – it’s just a fact of how most networked applications work. Data is read far more often than it’s written.
That’s why all relational databases and most document databases are optimized to cache frequently read items into memory – because that’s how the data is used in the vast majority of use cases.
In analytics though, the relationship is inverted:
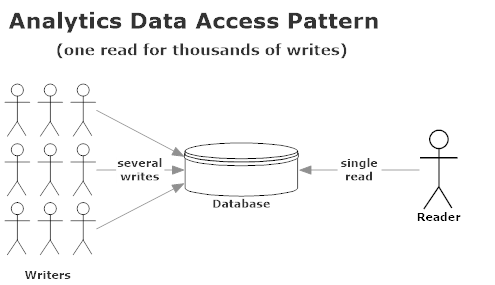
By the time a MarkedUp customer views a report on our dashboard, that data has been written to anywhere from 1,000 to 10,000,000 times since they viewed their report last. In analytics, data is written multiple orders of magnitude more frequently than it’s read.
So what implications does this have for our choice of database?
Database Criteria
Looking back to what went wrong with RavenDB, we determined that it was fundamentally flawed in the following ways:
- Raven’s indexing system is very expensive on disk, which makes it difficult to scale vertically – even on SSDs Raven’s indexing system would keep indexes stale by as much as three or four days;
- Raven’s map/reduce system requires re-aggregation once it’s written by our data collection API, which works great at low volumes but scales at an inverted ratio to data growth – the more people using us, the worse the performance gets for everyone;
- Raven’s sharding system is really more of a hack at the client level which marries your network topology to your data, which is a really bad design choice – it literally appends the ID of your server to all document identifiers;
- Raven’s sharding system actually makes read performance on indices orders of magnitude worse (has to hit every server in the cluster on every request to an index) and doesn’t alleviate any issues with writing to indexes – no benefit there;
- Raven’s map/reduce pipeline was too simplistic, which stopped us from being able to do some more in-depth queries that we wanted; and
- We had to figure out everything related to RavenDB on our own – we even had to write our own backup software and our own indexing-building tool for RavenDB; there’s very little in the way of a RavenDB ecosystem.
So based on all of this, we decided that our next database system needed to be capable of:
- Integrating with Hadoop and the Hadoop ecosystem, so we could get more powerful map/reduce capabilities;
- "Linear" hardware scale – make it easy for us to increase our service’s capacity with better / more hardware;
- Aggregate-on-write – eliminate the need to constantly iterate over our data set;
- Utilizing higher I/O – it’s difficult to get RavenDB to move any of its I/O to memory, hence why it’s so hard on disk;
- Fast setup time – need to be able to move quickly;
- Great ecosystem support – we don’t want to be the biggest company using whatever database we pick next.
The Candidates
Based on all of the above criteria, we narrowed down the field of contenders to the following:
- MongoDB
- Riak
- HBase
- Cassandra
Evaluation Process
The biggest factor to consider in our migration was time to deployment – how quickly could we move off of Raven and restore a high quality of service for our customers? We tested this in two phases:
- Learning curve of the database – how long would it take us to set up an actual cluster and a basic test schema?
- Acceptance test – how quickly could we recreate a median-difficulty query on any of these systems?
So we did this in phases, as a team – first up was HBase.
HBase
HBase was highly recommended to us by some of our friends on the analytics team at Hulu, so this was first on our list. HBase has a lot of attractive features and satisfied most of our technical requirements, save the most important one – time to deployment.
The fundamental problem with HBase is that cluster setup is difficult, particularly if you don’t have much JVM experience (we didn’t.) It also has a single point of failure (edit: turns out this hasn’t been an issue since 0.9x,) is a memory hog, and has a lot of moving parts. That being said, HBase is a workhorse – it’s capable of handling immensely large workloads. Ultimately we decided that it was overkill for us at this stage in our company and the setup overhead was too expensive. We’ll likely revisit HBase at some point in the future though.
Riak

One of our advisors is a heavy Riak user, so we decided it was worth exploring. Riak, on the surface, is a very impressive database – it’s heinously easy to set up a cluster and the HTTP REST API made it possible for us to test it using only curl.
After getting an initial 4-node cluster setup and writing a couple of “hello world” applications, we decided that it was time to move onto phase 2: see how long it would take to port a real portion of our analytics engine over to Riak. I decided to use Node.JS for this since there’s great node drivers for both Raven and Riak and it was frankly a lot less work than C#. I should point out that CorrugatedIron is a decent C# driver for Riak though.
So, it took me about 6 hours to write the script to migrate a decent-sized data set into Riak – just enough to simulate a real query for a single MarkedUp app.
Once we had the data stuffed into our Riak cluster I wrote a simple map/reduce query using JavaScript and ran it – took 90 seconds to run a basic count query. Yeesh. And this map/reduce query even used key filtering and all of the other m/r best practices for Riak.
Turns out that Map/Reduce performance with the JavaScript VM is atrocious and well-known in Riak. So, I tried a query using the embedded Erlang console using only standard modules – 50 seconds. Given the poor map/reduce performance and the fact that we’d all have to learn Erlang, Riak was out. Riak is a pretty impressive technology and it’s easy to set up, but not good for our use case as is.
{kind=link}
MongoDB

I’ve used MongoDB in production before and had good experiences with it. Mongo’s collections / document system is nearly identical to RavenDB, which gave it a massive leg up in terms of migration speed.
On top of that, Mongo has well-supported integration with Hadoop and its own aggregation framework.
Things were looking good for Mongo – I was able to use Node.JS to replicate the same query I used to test Riak and used the aggregation framework to get identical results within 3 hours of starting.
However, the issue with MongoDB was that it required us to re-aggregate all of our data regularly and introduced a lot of operational complexity for us. At small scale, it worked great, but under a live load it would be very difficult to manage Mongo’s performance, especially when adding new features to our analytics engine.
We didn’t write Mongo off, but we decided to take a look at Cassandra first before we made our decision.
Cassandra
![]()
We started studying Cassandra more closely when we were trying to determine if Basho had any future plans for Riak which included support for distributed counters.
Cassandra really impressed us from the get-go – it would require a lot more schema / data modeling than Riak or MongoDB, but its support for dynamic columns and distributed counters solved a major problem for us: being able to aggregate most statistics as they’re written, rather than aggregating them with map/reduce afterwards. On top of that, Cassandra’s slice predicate system gave us a constant-time lookup speed for reading time-series data back into all of our charts.
But Cassandra didn’t have all of the answers – we still needed map/reduce for some queries (ones that can’t or shouldn’t be done with counters) and we also needed the ability to traverse the entire data set.
Enter DataStax Enterprise Edition – a professional Cassandra distribution which includes Hive, Hadoop, Solr, and OpsCenter for managing backups and cluster health. It eliminated a ton of setup overhead and complexity for us and dramatically shortened our timeline to going live.
Evaluating Long-Term Performance
Cassandra had MongoDB edged out on features, but we still needed to get a feel for Cassandra’s performance. eBay uses Cassandra for managing time-series data that is similar to ours (mobile device diagnostics) to the tune of 500 million events a day, so we were feeling optimistic.
Our performance assessment was a little unorthodox – after we had designed our schema for Cassandra we wrote a small C# driver using FluentCassandra and replayed a 100GB slice of our production data set (restored from backup on a new RavenDB XL4 EC2 machine with 16 cores, 64GB of RAM, and SSD storage) to the Cassandra cluster; this simulated four month’s worth of production data written to Cassandra in… a little under 24 hours.
We used DataStax OpsCenter to graph the CPU, Memory, I/O, and latency over all four of our writeable nodes over the entire migration. We set our write consistency to 1, which is what we use in production.
Here are some interesting benchmarks – all of our Cassandra servers are EC2 Large Ubuntu 12.04 LTS machines:
- During peak load, our cluster completed 422 write requests per second – all of these operations were large batch mutations with hundreds rows / columns at once. We weren’t bottle-necked by Cassandra though – we were bottle-necked by our read speed pulling data out RavenDB.
- Cassandra achieved a max CPU utilization of 5%, with an average utilization of less than 1%.
- The amount of RAM consumed remained pretty much constant regardless of load, which tells me that our memory requirements never exceeded the pre-allocated buffer on any individual node (although we’ve spiked it since during large Hive jobs.)
- Cassandra replicated the contents of our 100GB RavenDB data set 3 times (replication factor of 3 is the standard) and our schema denormalized it heavily – despite both of those factors (which should contribute to data growth) Cassandra actually compressed our data set down to a slim 30GB, which provided us with storage savings of nearly 1000%! This is due to the fact that RavenDB saves its data as tokenized JSON documents, whereas everything is as byte arrays in Cassandra (layman’s terms.)
- Maximum write latency for Cassandra was 70731µs per operation with an an average write latency of 731µs. Under normal loads the average write latency is around 200µs. </ol> Our performance testing tools ran out of gas long before Cassandra did. Based on our ongoing monitoring of Cassandra we’ve observed that our cluster is operating at less than 2% capacity under our production load. We’ll see how that changes once we start driving up the amount of Hive queries we run on any given day. We never bothered running this test with MongoDB – Cassandra already had a leg up feature-set wise and the performance improvements were so remarkably good that we just decided to move forward with a full migration shortly after reviewing the results. ### Hive and Hadoop The last major piece of our stack is our map/reduce engine, which is powered by Hive and Hadoop. Hadoop is notoriously slow, but that’s ok. We don’t serve live queries with it – we batch data periodically and use Hive to re-insert it back into Cassandra. Hive is our tool of choice for most queries, because it’s an abstraction that feels intuitive to our entire team (lots of SQL experience) and is easy to extend and test on the fly. We’ve found it easy to tune and it integrates well with the rest of DataStax Enterprise Edition. ## Conclusion It’s important to think carefully about your data and your technology choices, and sometimes it can be difficult to do that in a data vacuum. Cassandra, Hive, and Hadoop ended up being the right tools for us at this stage, but we only arrived at that conclusion after actually doing live acceptance tests and performance tests. Your mileage may vary, but feel free to ask us questions in the comments!
Discussion, links, and tweets
I'm the CTO and founder of Petabridge, where I'm making distributed programming for .NET developers easy by working on Akka.NET, Phobos, and more..
Tweet Follow @Aaronontheweb